
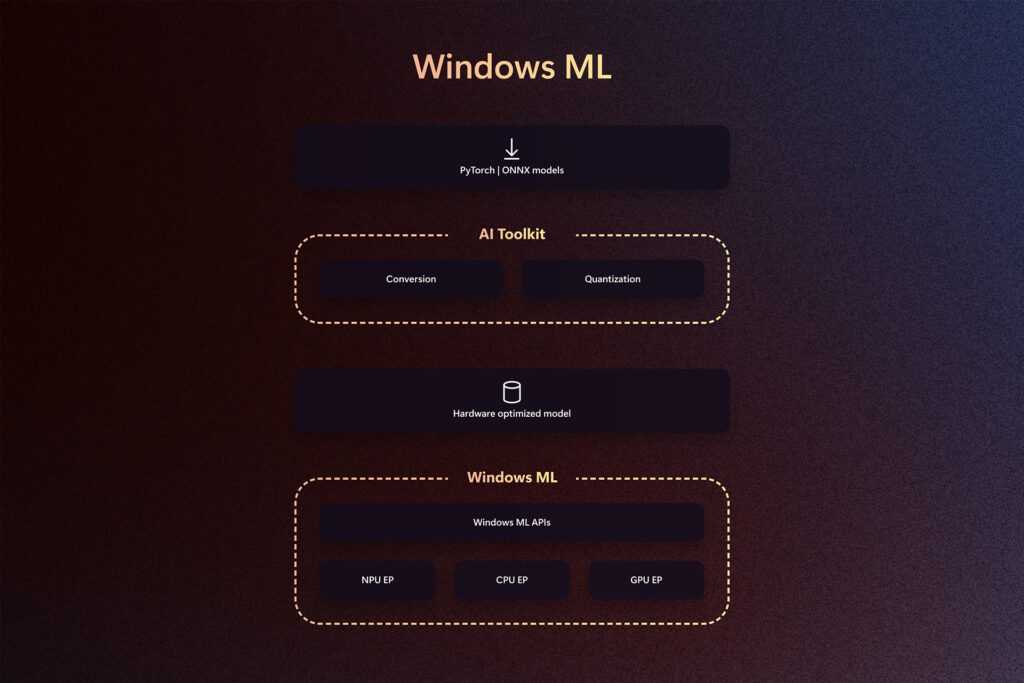
To support developers shipping production experiences in the increasingly complex AI landscape, we are thrilled to announce the public preview of Windows ML – a cutting-edge runtime optimized for performant on-device model inference and simplified deployment, and the foundation of Windows AI Foundry.
Windows ML is designed to support developers creating AI-infused applications with ease, harnessing the incredible strength of Windows’ diverse hardware ecosystem whether it’s for entry-level laptops, Copilot+ PCs or top-of-the-line AI workstations. It’s built to help developers leverage the client silicon best suited for their specific workload on any given device – whether it’s an NPU for low-power and sustained inference, a GPU for raw horsepower or CPU for the broadest footprint and flexibility.
Windows ML provides a unified framework so developers can confidently target Windows 11 PCs that are available today. It was built from the ground up to optimize model performance and agility and to respond to the speed of innovation in model architectures, operators and optimizations across all layers of the stack. Windows ML is an evolution of DirectML (DML) based on our learnings from the past year, listening to feedback from many developers, our silicon partners and our own teams developing AI experiences for Copilot+ PCs. Windows ML is designed with this feedback in mind, empowering our partners – AMD, Intel, NVIDIA, Qualcomm – to leverage the execution provider contract to optimize model performance, and match the pace of innovation.
Windows ML is powered by ONNX Runtime Engine (ORT), allowing developers to utilize the familiar ORT APIs. With ONNX as a native model format and support for pytorch to intermediate representations for the EPs, Windows ML ensures seamless integration with existing models and workflows. A key design aspect is leveraging and enhancing the existing ORT Execution Provider (EP) contract to optimize workloads for varied client silicon. Built in partnership with our Independent Hardware Vendors (IHVs), these execution providers are designed to optimize model execution on existing and emerging AI processors, enabling each to showcase their fullest capability. We’ve been working closely with AMD, Intel, NVIDIA and Qualcomm to integrate their EPs seamlessly in Windows ML, and are pleased to support the full set of CPUs, GPUs and NPUs from day one.
AMD fully supports Windows ML for Ryzen AI products, where their AMD GPU and AMD NPU Execution Provider enables maximum leverage of GPU and NPU in their platforms. Learn more.
“Windows ML seamlessly integrates across CPUs, GPUs and NPUs across the AMD’s portfolio including Ryzen AI 300 series, empowering ISVs to deliver groundbreaking AI experiences. This deep partnership between Microsoft and AMD is driving the future of AI on Windows, optimizing performance, efficiency and accelerating innovation.” — John Rayfield, Vice President of AI, AMD
Intel integrates the performance and efficiency of OpenVINO across CPUs, GPUs and NPUs with the development and deployment simplicity provided by Windows ML, enabling AI developers to more easily target the XPU that best fits their workload across the broad scale of products powered by Intel Core Ultra Processors. Learn more.
“Intel’s partnership with Microsoft on Windows ML supercharges AI app development by tightly integrating high-performance, high-accuracy workflows into the Windows ecosystem. Whether targeting CPU, GPU or NPU, developers can flexibly deploy across any XPU. With the Intel and OpenVINO integration, the focus shifts from plumbing to progress—unlocking faster, smarter AI-powered apps for Windows users everywhere.” – Sudhir Tonse Udupa, Vice President, AI PC Software Engineering, Intel
NVIDIA’s new TensorRT EP is the fastest way to execute AI models on NVIDIA RTX GPUs for the more than 100 million RTX AI PCs. When compared to the previous Direct ML implementation, TensorRT for RTX delivers up to 2x faster performance for AI workloads. Learn more.
“Today, Windows developers must often choose between broad hardware compatibility and full performance for AI workloads. Through Windows ML, developers can easily support a wide spectrum of hardware while achieving full TensorRT acceleration on NVIDIA GeForce RTX and RTX PRO GPUs.” – Jason Paul, Vice President of Consumer AI, NVIDIA
Qualcomm Technologies Inc. and Microsoft collaborated to develop and optimize Windows ML-based AI models and applications for the NPU found in Snapdragon X Series processor using the Qualcomm Neural Network Execution Provider (QNN EP). Learn more.
“The new Windows ML’s cutting-edge runtime not only optimizes on-device model inference but also simplifies deployment, making it easier for developers to harness the full potential of advanced AI processors in Snapdragon X Series platforms. Windows ML’s unified framework and support for diverse hardware, including our NPUs, GPUs and CPUs, ensures that developers can create AI applications that deliver exceptional performance and efficiency across a wide range of devices. We look forward to continuing our collaboration with Microsoft to drive innovation and velocity of development to bring the best AI experiences on Windows Copilot+ platforms.” – Upendra Kulkarni, VP, Product Management, Qualcomm Technologies, Inc.
There are a few key aspects to highlight for Windows ML:
- Simplified Deployment: Leveraging our infrastructure APIs, developers no longer need to create multiple builds of their app to target different silicon as they don’t have to bundle ONNX or execution providers in their application directly. We’ll make them available on the device and provide simple ways of registering them and enabling on-device ahead-of-time (AOT) model compilation.
- Advanced Silicon Targeting: Leverage device policies to optimize for low-power, high performance, or override to specify exactly what silicon to leverage for a specific model. In the future this will enable split processing for optimal performance – leveraging CPU or GPU for some pieces of a model and NPU for others.
- Performance: Windows ML is designed for performance; built on the foundations of ONNX and ONNX Runtime we see up to 20% improvement compared to other model formats. Over time we will add more Windows-specific capabilities for further optimization, like progressive memory mapping, partial model pinning and an optimized scheduler for parallel execution.
- Compatibility: Working with our IHV partners, Windows ML will guarantee conformance and compatibility, so you can rely on continued improvement while guaranteeing accuracy build-over-build for your models.
But it’s not just about the runtime, we are also introducing a robust set of tools in AI Toolkit for VS Code (AI Toolkit) to support model and app preparation – conversion to ONNX from PyTorch, quantization, optimization, compilation and profiling, to help developers ship production applications with proprietary or open-source models. These tools are specifically designed to simplify the process of preparing and shipping performant models via Windows ML without having to create multiple builds and complex logic.
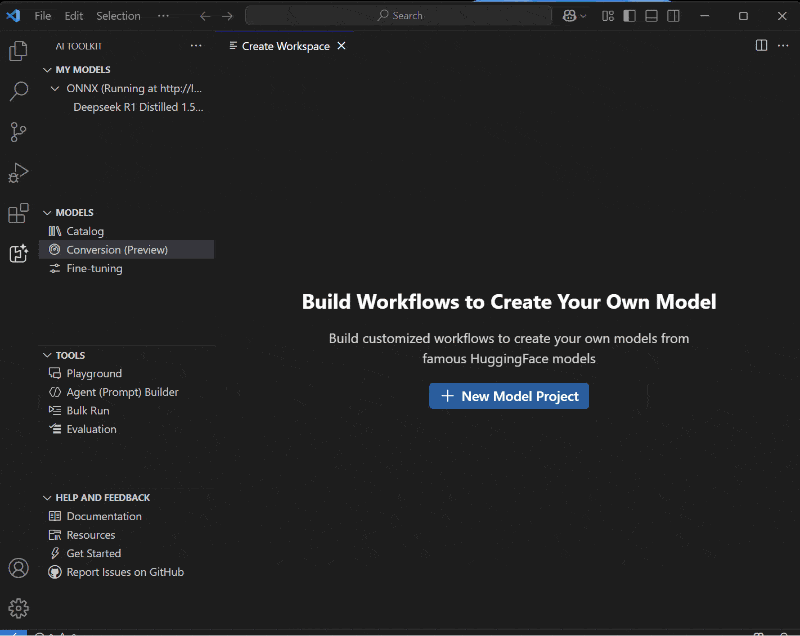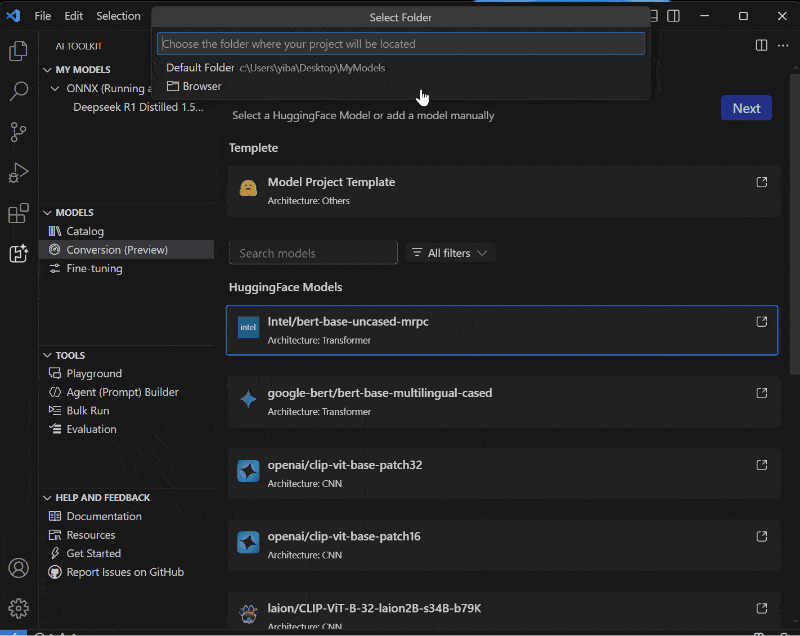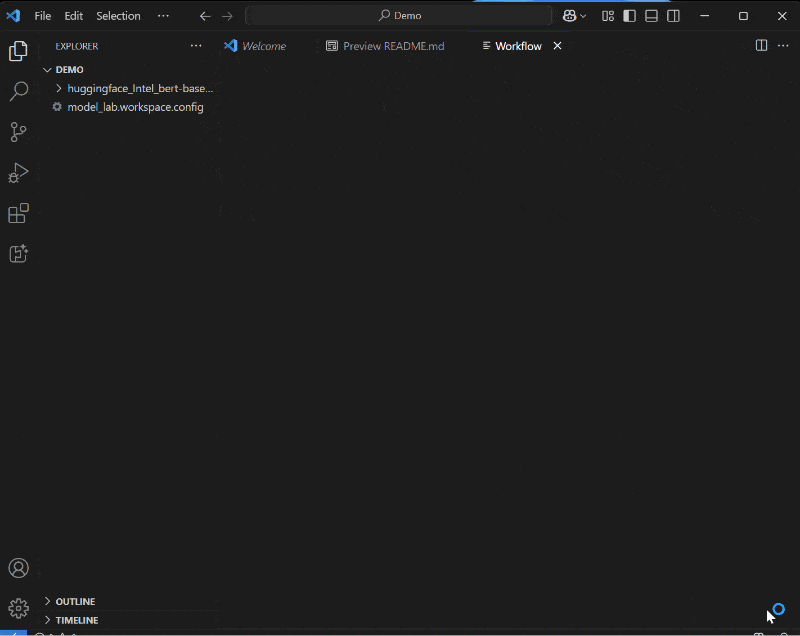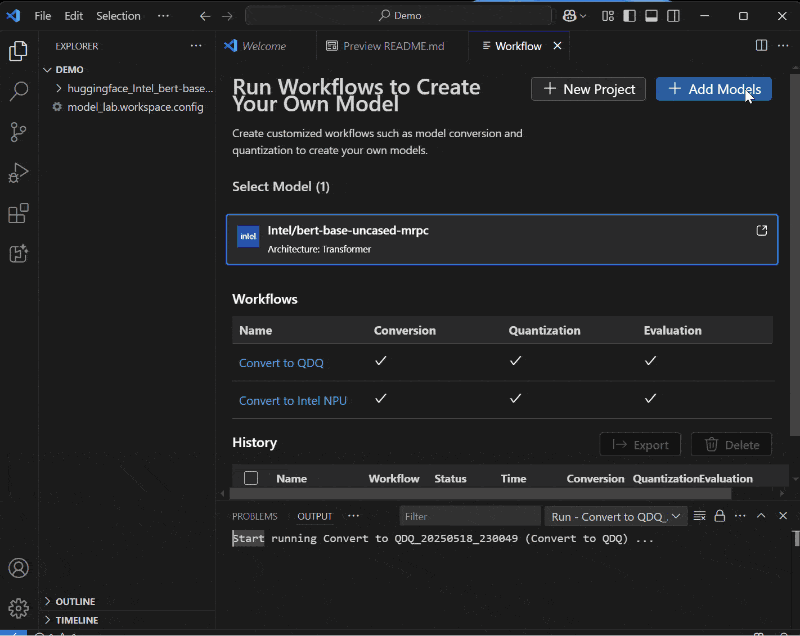
Windows ML is available in public preview starting today on all Windows 11 machines worldwide, offering developers the opportunity to explore its capabilities and provide feedback. The preview includes two layers of APIs:
- ML Layer: High-level APIs for runtime initialization, dependency management and helper APIs for establishing generative AI loops.
- Runtime Layer: Low-level ONNX Runtime APIs for fine-grained control of on-device inference.
To get started, install AI Toolkit, leverage one of our conversion and optimization templates, or start building your own. Explore documentation and code samples available on Microsoft Learn, check out AI Dev Gallery (install, documentation) for demos and more samples to help you get started with Windows ML.

While building Windows ML, it was important to us to receive feedback and perspective from app developers, especially those who are at the forefront of delivering AI-powered features and experiences. We shared early previews of Windows ML with a few leading developers who are testing integration with Windows ML and we’re thrilled by their early reactions:
Adobe (Volker Rölke – Senior ML Computer Scientist): “Adobe Premiere Pro and After Effects juggles terabytes of footage and heavy ML workloads. A reliable Windows ML API that delivers consistent performance across heterogeneous devices would remove huge obstacles and let us ship more exceptional features faster. Windows ML can help us take a hardware-agnostic approach with far less boiler-plate system checks and low-level decision-making.”
Bufferzone (Dr. Ran Dubin, CTO, Bufferzone): “At Bufferzone, we believe that AI powered PCs represent the future of endpoints. Windows ML simplifies integration challenges for ISVs, reduces time to market and fosters a higher adoption rate. As a result, customers will gain significantly more from their PCs which is a tremendous benefit for everyone.”
Filmora (Luyan Zhang – AI Product Manager): “The simplicity amazes me. Following Microsoft’s easier approach with ONNX models added to our app. We converted a complex AI feature to Windows ML in just 3 days.”
McAfee (Carl Woodward, Sr. Principal Engineer): “We’re excited about the efficiencies Windows ML can bring to the development and management of the new scam detection capabilities in McAfee+. Windows ML will allow us to focus on high-impact areas like model accuracy and performance, while providing confidence that AI components work well across the entire ecosystem, including new hardware revisions.”
Powder (Barthélémy Kiss – Co-founder and CEO at Powder): “Powder is an early adopter of Windows ML, and it has enabled us to integrate models 3x faster, transforming speed into a key strategic advantage. With Windows 11 handling the heavy lifting across silicon providers, now we can focus more on doing what our Powder developers do best – developing more magical AI video experiences in less time, and at a drastically lower operating cost.”
Reincubate (Aidan Fitzpatrick – CEO): “We’re committed to supporting and making the most of new AI hardware chipsets on day one. And Windows ML should be a powerful tool in helping us to move at the speed of silicon innovation. For us, the holy grail is being able to take a single high precision model and have it just work seamlessly across Windows silicon and we think Windows ML is an important step in the right direction.”
Topaz Labs (Dr. Suraj Raghuraman – Head of AI Engine): “Windows ML will reduce our installer size tremendously, going down from gigabytes to megabytes. This will allow our users to do more things on their disk, because the model storage requirement goes down as well. Since Windows ML relies heavily on ONNX runtime, it was really easy for us to integrate it. We integrated the entire API within a couple of days and it has been a seamless experience from an innovation standpoint.”
Whether you’re a seasoned AI developer or exploring ML for the first time, Windows ML empowers you to focus on innovation rather than infrastructure management, enabling you to delight your customers with AI-infused applications with reduced app footprints. Windows ML will be generally available later this year. In the meantime, we look forward to your feedback and seeing how you leverage Windows ML to create solutions that redefine possibilities. Join the Windows ML journey today and be part of the next wave of AI innovation!