

A new era of AI
One year ago, Microsoft introduced small language models (SLMs) to customers with the release of Phi-3 on Azure AI Foundry, leveraging research on SLMs to expand the range of efficient AI models and tools available to customers.
Today, we are excited to introduce Phi-4-reasoning, Phi-4-reasoning-plus, and Phi-4-mini-reasoning—marking a new era for small language models and once again redefining what is possible with small and efficient AI.
Reasoning models, the next step forward
Reasoning models are trained to leverage inference-time scaling to perform complex tasks that demand multi-step decomposition and internal reflection. They excel in mathematical reasoning and are emerging as the backbone of agentic applications with complex, multi-faceted tasks. Such capabilities are typically found only in large frontier models. Phi-reasoning models introduce a new category of small language models. Using distillation, reinforcement learning, and high-quality data, these models balance size and performance. They are small enough for low-latency environments yet maintain strong reasoning capabilities that rival much bigger models. This blend allows even resource-limited devices to perform complex reasoning tasks efficiently.
Phi-4-reasoning and Phi-4-reasoning-plus
Phi-4-reasoning is a 14-billion parameter open-weight reasoning model that rivals much larger models on complex reasoning tasks. Trained via supervised fine-tuning of Phi-4 on carefully curated reasoning demonstrations from OpenAI o3-mini, Phi-4-reasoning generates detailed reasoning chains that effectively leverage additional inference-time compute. The model demonstrates that meticulous data curation and high-quality synthetic datasets allow smaller models to compete with larger counterparts.
Phi-4-reasoning-plus builds upon Phi-4-reasoning capabilities, further trained with reinforcement learning to utilize more inference-time compute, using 1.5x more tokens than Phi-4-reasoning, to deliver higher accuracy.
Despite their significantly smaller size, both models achieve better performance than OpenAI o1-mini and DeepSeek-R1-Distill-Llama-70B at most benchmarks, including mathematical reasoning and Ph.D. level science questions. They achieve performance better than the full DeepSeek-R1 model (with 671-billion parameters) on the AIME 2025 test, the 2025 qualifier for the USA Math Olympiad. Both models are available on Azure AI Foundry and HuggingFace, here and here.
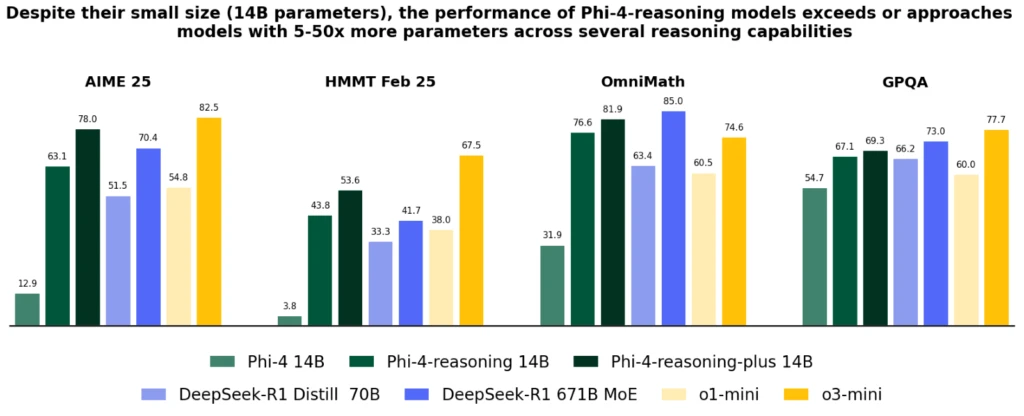

Phi-4-reasoning models introduce a major improvement over Phi-4, surpass larger models like DeepSeek-R1-Distill-70B and approach Deep-Seek-R1 across various reasoning and general capabilities, including math, coding, algorithmic problem solving, and planning. The technical report provides extensive quantitative evidence of these improvements through diverse reasoning tasks.
Phi-4-mini-reasoning
Phi-4-mini-reasoning is designed to meet the demand for a compact reasoning model. This transformer-based language model is optimized for mathematical reasoning, providing high-quality, step-by-step problem solving in environments with constrained computing or latency. Fine-tuned with synthetic data generated by Deepseek-R1 model, Phi-4-mini-reasoning balances efficiency with advanced reasoning ability. It’s ideal for educational applications, embedded tutoring, and lightweight deployment on edge or mobile systems, and is trained on over one million diverse math problems spanning multiple levels of difficulty from middle school to Ph.D. level. Try out the model on Azure AI Foundry or HuggingFace today.
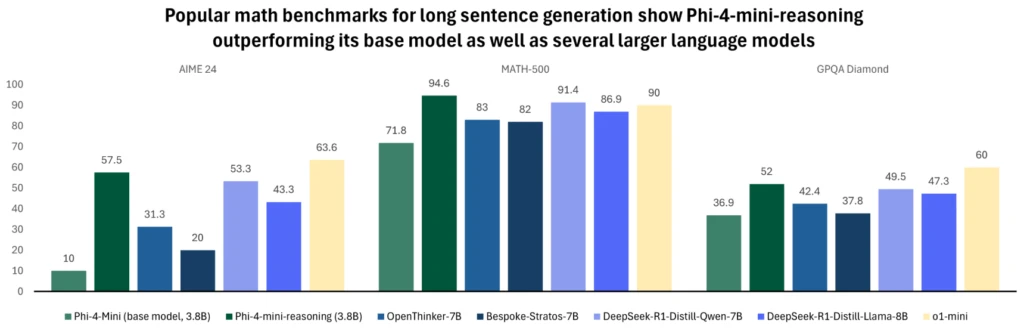
For more information about the model, read the technical report that provides additional quantitative insights.
Phi reasoning models in action
Phi’s evolution over the last year has continually pushed this envelope of quality vs. size, expanding the family with new features to address diverse needs. Across the scale of Windows 11 devices, these models are available to run locally on CPUs and GPUs.
As Windows works towards creating a new type of PC, Phi models have become an integral part of Copilot+ PCs with the NPU-optimized Phi Silica variant. This highly efficient and OS-managed version of Phi is designed to be preloaded in memory, and available with blazing fast time to first token responses, and power efficient token throughput so it can be concurrently invoked with other applications running on your PC.
It is used in core experiences like Click to Do, providing useful text intelligence tools for any content on your screen, and is available as developer APIs to be readily integrated into applications—already being used in several productivity applications like Outlook, offering its Copilot summary features offline. These small but mighty models have already been optimized and integrated to be used across several applications across the breadth of our PC ecosystem. The Phi-4-reasoning and Phi-4-mini-reasoning models leverage the low-bit optimizations for Phi Silica and will be available to run soon on Copilot+ PC NPUs.
Safety and Microsoft’s approach to responsible AI
At Microsoft, responsible AI is a fundamental principle guiding the development and deployment of AI systems, including our Phi models. Phi models are developed in accordance with Microsoft AI principles: accountability, transparency, fairness, reliability and safety, privacy and security, and inclusiveness.
The Phi family of models has adopted a robust safety post-training approach, leveraging a combination of Supervised Fine-Tuning (SFT), Direct Preference Optimization (DPO), and Reinforcement Learning from Human Feedback (RLHF) techniques. These methods utilize various datasets, including publicly available datasets focused on helpfulness and harmlessness, as well as various safety-related questions and answers. While the Phi family of models is designed to perform a wide range of tasks effectively, it is important to acknowledge that all AI models may exhibit limitations. To better understand these limitations and the measures in place to address them, please refer to the model cards below, which provide detailed information on responsible AI practices and guidelines.
Learn more here:
- Try out the new models on Azure AI Foundry.
- Read the Phi Cookbook.
- Read about Phi reasoning models on edge devices.
- Learn more about Phi-4-mini-reasoning.
- Learn more about Phi-4-reasoning.
- Learn more about Phi-4-reasoning-plus.
- Read more about Phi reasoning on the Educators Developer blog.
The post One year of Phi: Small language models making big leaps in AI appeared first on Microsoft Azure Blog.