
Introduction
This blog is the first installment in a new series of technical content designed to provide insights into the AI innovation on Windows. Today we will share how the Applied Sciences team used a multi-interdisciplinary approach to achieve a breakthrough in power efficiency, inference speed and memory efficiency for a state-of-the-art small language model (SLM), Phi Silica. Integrated into Windows 11 Copilot+ PCs (starting with Snapdragon X Series), this SLM powers several features of the latest generation of Copilot+ PC experiences: Click to Do (Preview), on-device rewrite and summarize capabilities in Word and Outlook, and a turnkey pre-optimized SLM for developers to utilize.
Background
In May, we introduced Copilot+ PCs, these devices include a Neural Processing Unit (NPU) capable of over 40 trillion operations per second (TOPS). During our May announcement, we also unveiled Phi Silica, the new on-device SLM available starting with Snapdragon X Series NPUs. Phi Silica is the sister-series of Phi models that leverages the NPU on Copilot+ PCs. At Ignite in November, we also announced that developers can access Phi Silica API starting in January 2025. Developers can bring language intelligence capabilities into their apps without needing to worry about model optimization or customization as Phi Silica is pre-tuned and ships inbox.
NPU devices with all day battery life claims run sustained AI workloads over long periods of time, in the background, with minimal impact to system fundamentals and resources. Connected to, and enhanced by the cloud, Copilot+ PCs can now achieve a level of performance never seen before – they are up to 20x more powerful1 and up to 100x as efficient2 for running AI workloads, and have smaller footprints than GPUs per TOPS/Watt/dollar. NPUs can sustain AI workloads that exhibit emergent behavior (3 to 7B parameter SLMs) in a semi-continuous loop, allowing users to make limitless low-latency queries to the model, without incurring additional subscription fees. This is a paradigm shift in compute; we now have the ability to run powerful reasoning agents as part of background operating system (OS) services, unlocking the potential for innovation across the range of our applications and services.
Copilot+ PC: A new AI era at work
Original floating-point model
Phi Silica is based on a Cyber-EO compliant derivative of Phi-3.5-mini, developed specifically for Windows 11. It has a 4k context length, supports multiple languages including Tier 1 languages and others [English, Chinese (Simplified), French, German, Italian, Japanese, Portuguese, Spanish] and includes key improvements necessary for in-product experiences.
A language model, such as Phi, consists of several components:
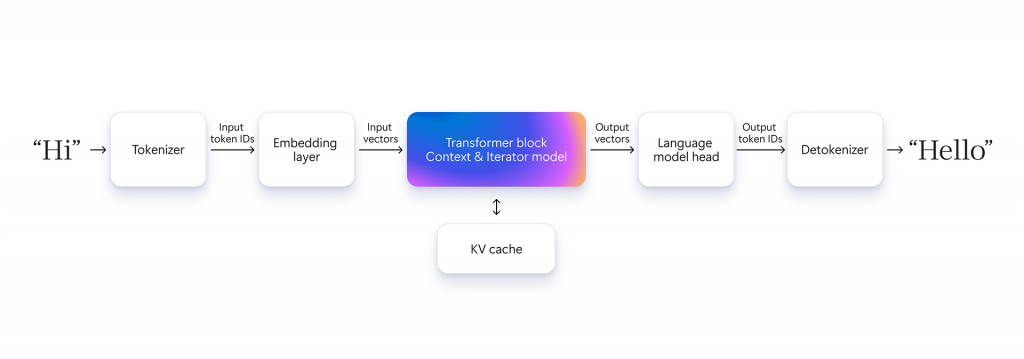
- The tokenizer breaks down the input text into smaller units and maps them to an index based on a pre-specified vocabulary. Tokenization forms a mapping between the language of humans and the language of models.
- The detokenizer performs the reverse operation.
- The embedding model transforms every discrete input token ID into a continuous, higher dimensional vector that captures semantic information in the space of language as understood by the language model. The direction of the normalized embedding vector encodes the context and the meaning of the text.
- The transformer block transforms these incoming vectors to output vectors (or output hidden states) that point in the direction of the token that should follow the current one.
- The language model head computes the most likely token based on the output vectors.
Generating a response to a prompt consists of two distinct phases of operation of the transformer block:
- Context processing: The language model processes input tokens to compute the key-value (KV) cache and generate hidden states and the first token. This involves intense parallel computation, mainly matrix multiplications, requiring high computational power.
- Token iteration: Tokens are generated one by one (i.e. autoregressively) and each new token becomes part of the extended context to predict the next one. Generation stops when an end token is produced, or a user-defined condition is met.
Running the aforementioned stages for even SLMs such as Phi, with their billions of parameters, can place considerable strain on your device. The context processing stage requires significant computational resources, which impacts the CPU and running applications, and involves high power usage when GPUs are employed due to their efficiency in TOPS per Watt. In contrast, the token iteration stage demands substantial memory for storing and accessing the KV cache for each token generation step. While it needs less computation, efficient memory access is crucial for maintaining performance. Memory constraints make efficient token generation challenging.
NPUs within Copilot+ PCs are built to be power-efficient, capable of executing several TOPS within a single-digit Watt range. On Copilot+ PC devices with Snapdragon X Elite processors, Phi Silica’s context processing consumes only 4.8mWh of energy on the NPU, while the token iterator exhibits a 56% improvement in power consumption compared to operation on the CPU. Consequently, we can execute Phi Silica on your device without burdening the CPU and GPU, ensuring efficient memory and power consumption, thereby allowing this highly capable and versatile model to run seamlessly, with minimal impact on your primary applications and experiences.
As NPUs are domain-specific processors, we have employed various techniques to achieve an optimal balance between efficiency and performance without compromising accuracy. We are eager to share these techniques and hope they can be applied to other small language models as well. Our discussion will primarily focus on optimizing and offloading the transformer block to the NPU. The tokenizer, embedding and language model head are not compute-intensive but involve lookups; therefore, we allocate these tasks to the CPU.
Creating Phi Silica
Considering the size of the original floating-point model, memory limitations of the target hardware, as well as the desired performance metrics in terms of speed, memory usage and power efficiency, it was clear that Phi Silica should have the following characteristics:
- 4-bit weight quantization to ensure high speed and a low memory footprint during inferencing
- Low idle memory consumption to support pinned memory and eliminate initialization costs
- Rapid time to first token for shorter prompts to enhance interactivity
- A context length of 2k or greater to ensure real-world usability
- NPU-based operation to achieve power efficiency in sustained usage
- High accuracy across multiple languages
- Small model disk size to make distribution at Windows scale efficient
We designed Phi Silica with these goals in mind for the current generation NPUs. In doing so, we pushed the envelope on what’s possible today across several levels of the stack such as post-training quantization, efficient resource use in inference software and targeted silicon-specific optimizations across operator placement and model graph. The result is a model that delivers, with the bulk of compute offloaded:
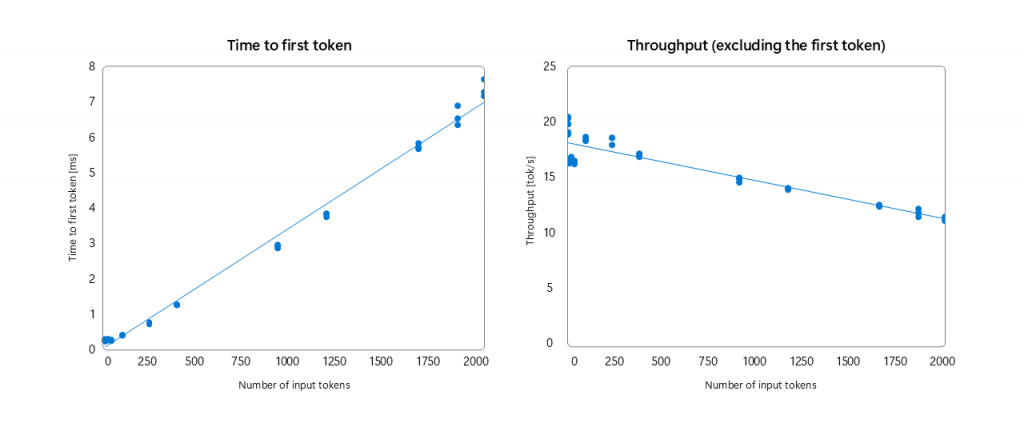
- Time to first token: 230ms for short prompts
- Throughput rate: Up to 20 tokens/s
- Context length: 2k (with support for 4k coming shortly)
- Sustained NPU-based context processing and token iteration
Real-time demo of Phi Silica running on Copilot+ PCs (Snapdragon X Elite)
Post-training quantization
In a bid to achieve true low-precision inference by quantizing both weights and activations, Microsoft and academic researchers collaborated to create QuaRot: Outlier-Free 4-Bit Inference in Rotated LLMs (pronounced “carrot”). QuaRot acts as a pre-quantization modifier, enabling the end-to-end quantization of language models, including all weights, activations and KV cache, down to 4-bits. By rotating language models to remove outliers from the hidden state without affecting the output, QuaRot facilitates high-quality quantization at lower bit-widths. The ingenuity of QuaRot is anchored in two fundamental concepts:
- Incoherence processing: Previous weight-only quantization methods such as QuIP and QuIP# employ rotations to pre-multiply and post-multiply the weight matrices (and Hessians). A weight matrix has high incoherence when its largest element is an outlier relative to the average element’s magnitude, making it difficult to quantize. Incoherence processing reduces the incoherence in weight matrices by rotating them to make quantization easier. However, this comes at an increased computational cost of rotations and de-rotations for each weight matrix.
- Computational invariance: QuaRot extends the idea of computational invariance introduced in SliceGPT. Computational invariance means that a transformation to the weight matrices does not change the output. QuaRot uses random Hadamard transforms for the rotations and applies incoherence processing in a computationally invariant manner. This reduces the computational overhead because the rotations and de-rotations across layers can be fused and skipped, leaving only an ingoing and outgoing rotation outside the transformer block. Furthermore, QuaRot allows activations to be incoherence-processed, making activation quantization easier.
QuaRot uses rotations to remove outliers to make quantization easier
This results in an equivalent network in a rotated space, allowing activations, weights and KV cache to be quantized to 4-bits, with minimal accuracy loss.
Realizing gains from a 4-bit model
The 4-bit weight quantization optimized our memory footprint. However, adapting QuaRot to enable 4-bit quantized weight model inference on an NPU necessitated several adaptations due to specifics of quantization support in the software stack for NPUs. The final 4-bit Phi Silica model comprises of:
- Rotated network: In the base floating-point ONNX model, we convert the LayerNorm transformer network into an RMS-Norm transformer network and used fused Hadamard rotations to obtain an equivalent rotated network.
- Embedding layer: A fused one-time ingoing QuaRot rotation.
- Activations: Asymmetric per-tensor round-to-nearest quantization to unsigned 16-bit unsigned integers from ONNX.
- Weights: Symmetric per-channel quantization to 4-bit integers from QuaRot with GPTQ, copied into the rotated network.
- Linear layers: To get the best latency on the current NPU stack, we converted all linear layers into 1×1 convolutional layers (Conv2D). This improved efficiency for the specific matrix sizes involved in Phi Silica.
- Selective mixed precision: To further enhance accuracy, we identified several quantized weights that exhibited larger reconstruction errors and selectively quantized them using per-tensor 8-bit quantization. This is advisable for NPU-based inference to mitigate the effect of static quantization of all activations, but it is important to use this method sparingly to keep the overall model size small. In practice, we used 8-bit quantization for 4-8 out of 128 weight matrices.
- Language model head: A fused one-time outgoing QuaRot de-rotation. We also quantize the language model head with 4-bit block-wise quantization to keep the memory usage low.
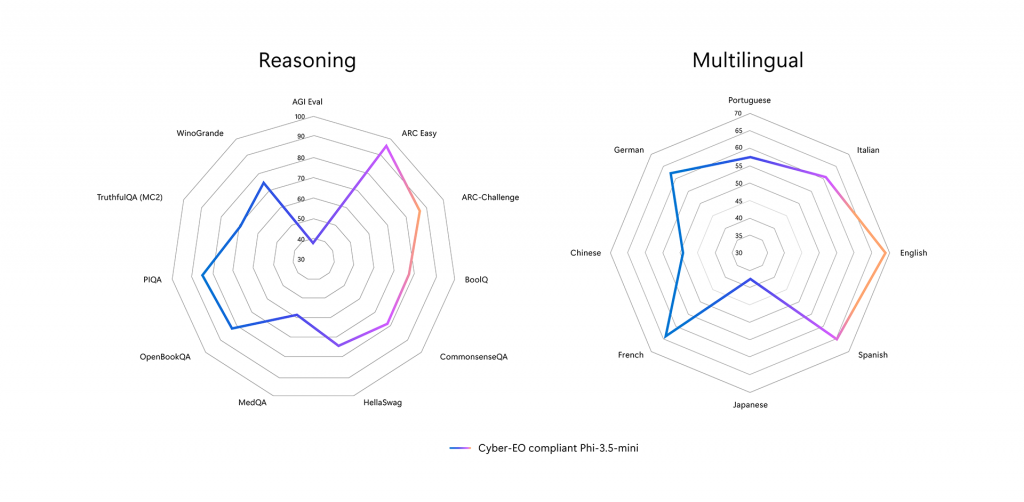
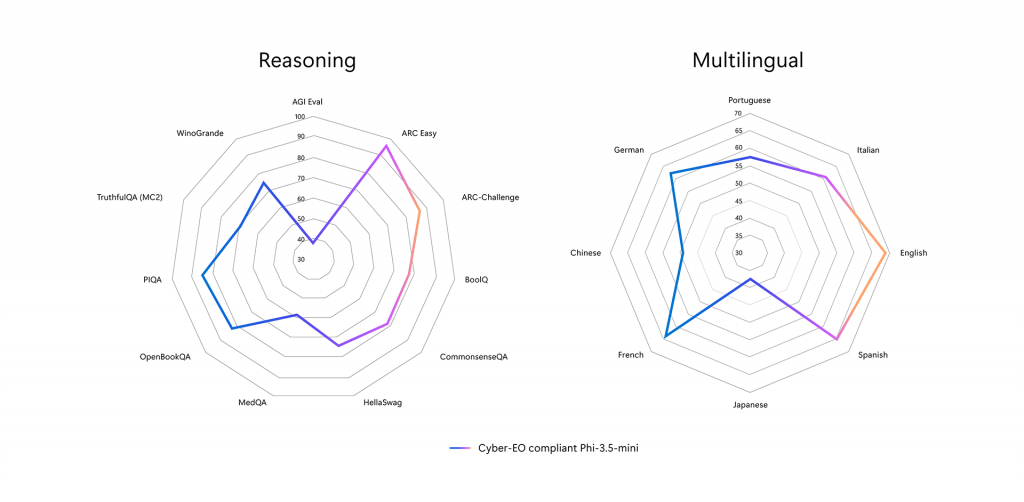
We observed that QuaRot significantly improves quantization accuracy, compared to the de-facto round-to-nearest quantization, particularly for low granularity settings such as per-channel quantization. The following table presents benchmark results before and after 4-bit quantization.
| Zero-shot task (lm-eval harness) | Floating-point model
(%) |
4-bit QuaRot weights
(float activations) (%) |
| piqa | 80.47 | 79.76 |
| winogrande | 72.77 | 72.38 |
| arc_challenge | 63.48 | 60.49 |
| arc_easy | 85.69 | 82.74 |
| hellaswag | 77.14 | 75.13 |
| mmlu_abstract_algebra | 45.00 | 38.00 |
| mmlu_business_ethics | 76.00 | 73.00 |
| mmlu_college_computer_science | 57.00 | 48.00 |
| mmlu_college_mathematics | 40.00 | 38.00 |
| mmlu_conceptual_physics | 71.91 | 67.23 |
| mmlu_formal_logic | 53.97 | 50.00 |
| mmlu_machine_learning | 57.14 | 52.67 |
Improving memory efficiency
Keeping Phi Silica persistent in memory to handle sustained inference requires the memory usage of the model to be tightly bounded. We optimized the memory efficiency of the model through an iterative process of accurate memory measurements and addressing the most pressing memory issue. Some key techniques included:
- Weight sharing: The context processor and token iterator share the same set of quantized weights and most activation quantization parameters, which halved memory usage and accelerated model initialization. This was achieved by having the two model graphs reference the shared weights in ONNX Runtime.
- Memory-mapped embeddings: The embedding layer scales with the vocabulary size and the embedding dimension. Using a memory-mapped file for the embedding matrix and implementing the layer as a lookup table effectively reduced the dynamic memory footprint to zero because it eliminated the need for this large matrix to be held in memory.
- Disabling arena allocator: By default, ONNX Runtime uses an arena allocator, which results in excessive pre-allocation of memory. Arena allocation helps to reduce frequent memory allocations and deallocations and can be beneficial in some cases, but it leads to higher initial memory usage. For Phi Silica, the pattern of memory usage is pre-determined, so disabling this behavior improved memory efficiency overall.
The combined effect of these changes, with the 4-bit quantized model led to a ~60% reduction in memory usage.
Expanding the context length
Expanding the context length beyond the sequence length of the context processor despite static tensor shape requirements of the NPU-facing software stack was crucial for enabling real-world applications. To expand the context length and enable streaming prompt processing, we came up with two key innovations that work in tandem:
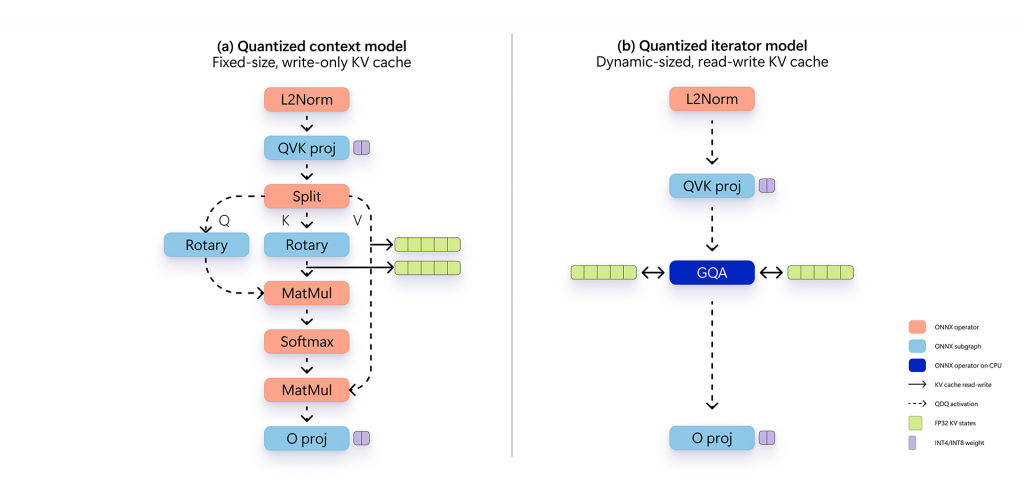
Sliding window: Instead of processing the entire prompt, we process it in smaller chunks of size N (with padding applied to the last chunk if necessary). This reduces the effective sequence length of the chunked context model to N while keeping the total context length the same as before. We process each chunk sequentially and update the KV cache to maintain history. We use N=64. This approach unlocks faster processing of shorter prompts without sacrificing speed on longer prompts, i.e. prompt processing time scales with the prompt length.
Context processing and token iteration process within Phi Silica
Dynamic and shared KV cache: A context processor that runs wholly on the NPU but has a read-only key-value cache is highly efficient, but this limits the context length to the sequence length of the context processor. We experimented with different ways of splitting context processing across the NPU and CPU to find a good balance of speed and flexibility. The best configuration involved doing only the GroupQueryAttention operation on the CPU. This enabled a read-write, dynamic-sized KV cache for context-processing, which can then be expanded during iteration for token generation. A dynamic-sized read-write KV cache can be shared across context processing chunks, which maintains history, but also across context processing and token iteration which improves memory efficiency. Input/Output binding pre-allocates sufficient memory during context processing and enables context processing and token iteration to share a single KV cache efficiently; this improves runtime latency significantly. Memory efficiency of KV cache management is crucial because the context KV cache scales quadratically with the context length.
The resulting Phi Silica model features improved first token latency for shorter prompts and improves memory efficiency while retaining most of the power-efficiency afforded by a largely NPU-based operation.
Safety alignment, Responsible AI and content moderation
The floating point model from which Phi Silica is derived has undergone safety alignment using a five stage ‘break-fix’ methodology similar to the one outlined in this technical report: Phi-3 Safety Post-Training: Aligning Language Models with a “Break-Fix” Cycle.
Phi Silica model, the system design and the API undergo a Responsible AI impact assessment and deployment safety board reviews. Local content moderation is available in the Phi Silica developer API. An overview of this process can be reviewed here: Get started with Phi Silica in the Windows App SDK.
Closing
We pushed the boundaries of what’s possible with today’s NPUs in a rapidly evolving, complex technical landscape. By advancing quantization research, we have achieved remarkable gains in three critical areas with Phi Silica: memory efficiency, power efficiency and inference latencies, without compromises in quality or functionality. These results underscore Microsoft’s commitment to developing models that are not only powerful in capability but also highly efficient. By including Phi Silica in the operating system on Copilot+ PCs, Microsoft is ensuring that these powerful and efficient models are seamlessly integrated into Windows 11 experiences on Copilot+ PCs, empowering users to achieve more with their devices.
1 Tested April 2024 using debug application for Windows Studio Effects workload comparing pre-release Copilot+ PC builds with Snapdragon Elite X 12 Core to Windows 11 PC with Intel 12th gen i7 configuration.
2 Tested April 2024 using Phi SLM workload running 512-token prompt processing in a loop with default settings comparing pre-release Copilot+ PC builds with Snapdragon Elite X 12 Core and Snapdragon X Plus 10 core configurations (QNN build) to Windows 11 PC with NVIDIA 4080 GPU configuration (CUDA build).