
We are excited to announce the public preview of Azure Storage Actions, a fully managed platform that helps you automate data management tasks for Azure Blob Storage and Azure Data Lake Storage.
With exponential growth in data estates, organizations face spiraling challenges with data management. Effective data management is essential for businesses to fully leverage their data assets, meet compliance regulations, reduce costs, and safeguard sensitive information. Today, the tools and methods available to manage massive data assets are laborious, and increasing resource investments to manage data at the same pace as the increase in data volumes is unsustainable. Storage customers need an efficient mechanism to manage thousands of datasets with billions of objects across all regions holistically and consistently.
Azure Storage Actions transforms the way you manage vast data assets in your object storage and data lakes, with a faster time to value. Its serverless infrastructure delivers a reliable platform that scales to your data management needs, without provisioning or managing any resources. Using a no-code experience, you can define the conditional logic for processing objects without requiring any programming expertise. The tasks you compose can securely operate on multiple datasets that have similar requirements with just a few clicks. Monitoring overhead is minimized through views that summarize results at a glance, along with filters and drilldowns for details. This release supports cost optimization, data protection, rehydration from archive, tagging, and several other use cases, with more to follow, for Azure Blob Storage and Azure Data Lake Storage.
Explore
Azure Data Lake Storage
How Azure Storage Actions works
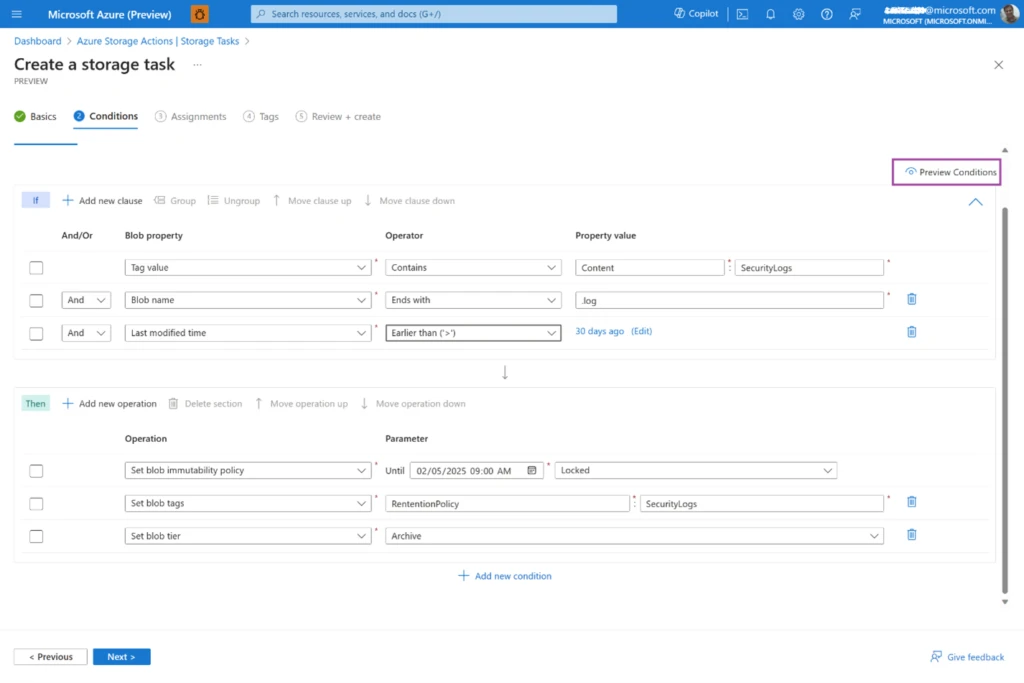
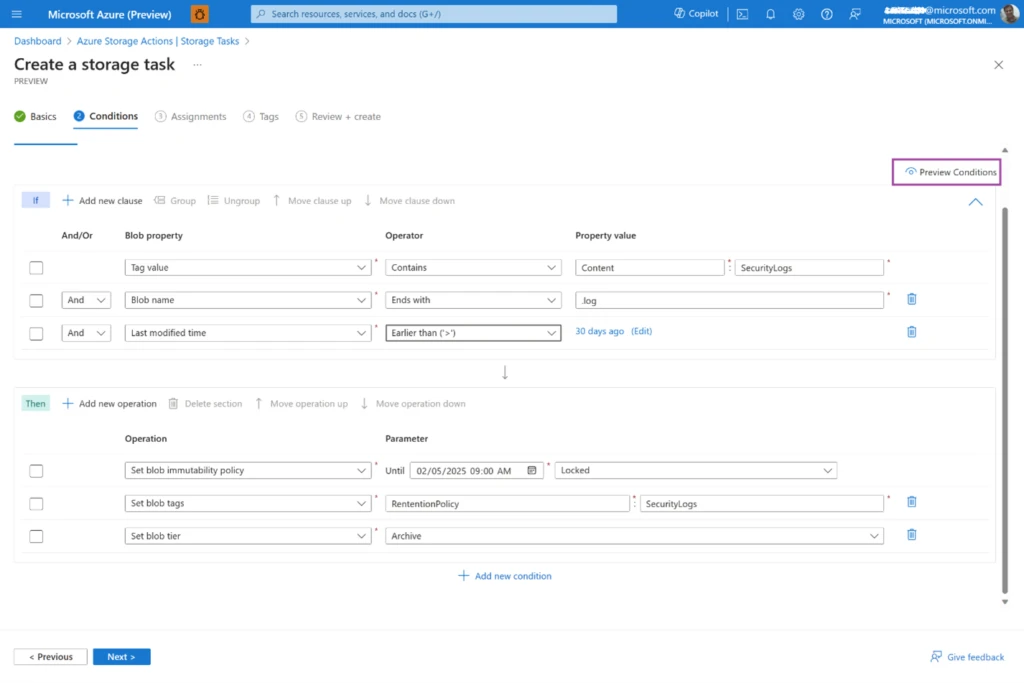
Using Azure Storage Actions, you can compose, validate, and deploy data management tasks in minutes. These tasks can be configured to execute on a schedule or on demand.
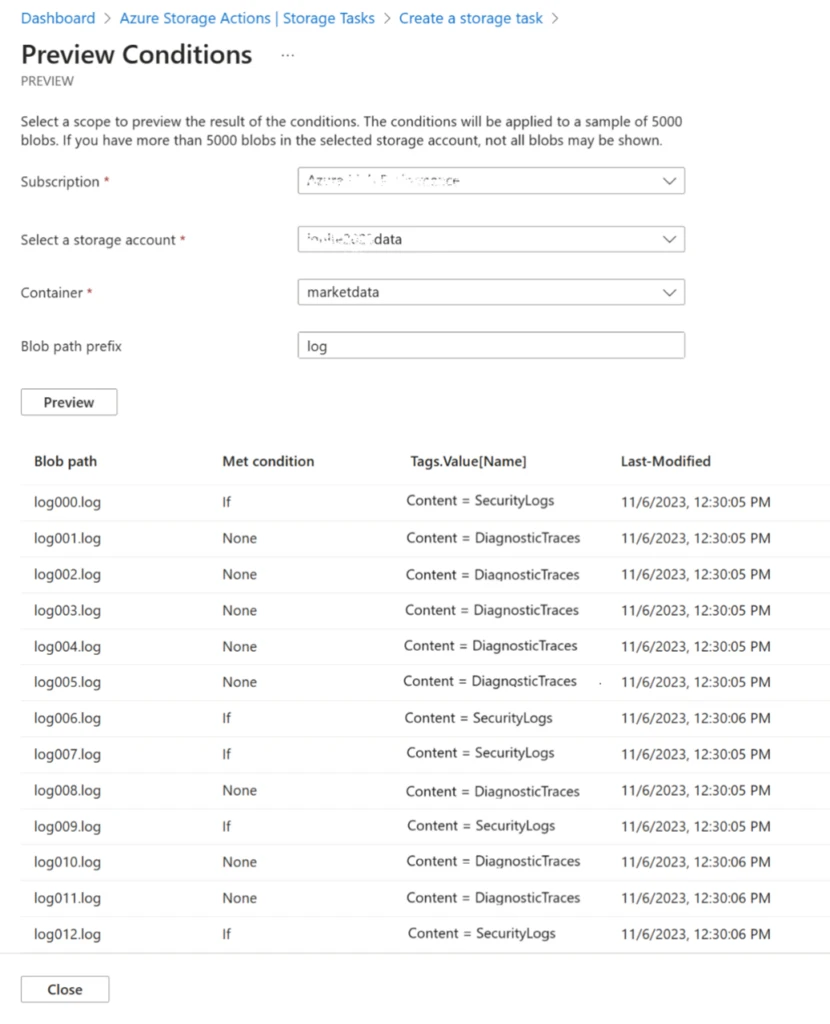
The Azure portal interface enables you to compose a condition that identifies the blobs you want to operate on, and the operations you want to invoke. The integrated validation experience allows you to safely verify the condition against your production data without executing any actions—it shows you which blobs meet the condition and the operations that would be invoked on them if the task were executed. Tasks can be assigned to execute across any storage accounts in the same Microsoft Entra ID tenant. The service automatically provisions, scales, and optimizes the resources for recurring or one-off task executions as appropriate. Aggregate metrics and dashboards summarize operations visually, along with drilldowns into detailed reports that enable you to intervene minimally when and where required.
Azure Storage Actions can also be managed programmatically through REST APIs and the Azure SDK. It includes support for PowerShell, Azure Command-Line Interface (CLI), and Azure Resource Manager (ARM) templates.
Supported operations: The current release includes support for built-in operations on Azure Blob Storage and Azure Data Lake Storage, including setting time-based retention, managing legal holds, changing tiers, managing blob expiry, setting blob tags, and deleting or undeleting blobs. Forthcoming releases will expand support for the feature with additional operations.
Why use Azure Storage Actions
Automating your data management operations using Azure Storage Actions offers several advantages:
Boosts your productivity by minimizing the effort required to automate common data management tasks.
Minimizes overhead involved in provisioning or managing infrastructure.
Provides assurance with the integrated validation experience in the no-code interface for error-free application to your production data.
Simplifies reuse by enabling you to create a task once and deploy it to any storage accounts in just a few clicks.
Encourages consistency in use of blob tags and metadata in conditions and operations.
Example use cases
Large data lakes can have thousands of data sets with a mix of object types that require different types of processing. Depending on their attributes, individual objects in a blob container may require specific retention or expiry periods, different tiering transitions, tagging using different labels, and such. With Azure Storage Actions you can define tasks that scan billions of blobs, examine each blob based on dozens of its properties—such as file extension, naming pattern, index tags, blob metadata, or system properties like creation time, content type, blob tier, and more—and determine how it should be processed. There are many recurring or one-off use cases that can be simplified using this approach, for example:
Learn More
Azure Blob Storage
Retention and expiry based on object tags: One of our global financial services customers uses Azure Blob Storage to ingest their customer service call recordings which include blob tags that identify whether a trading order was placed, account info was updated, and such. These recordings have different retention requirements based on this call type. They can now use Azure Storage Actions to define a task that automatically manages the retention and expiry durations of ingested recordings using a combination of blob tags and creation time.
Flexible data protection in datasets: Another customer, a leading travel services company, uses blob versioning and snapshots, but the thousands of datasets in the storage account have differing data protection requirements. Sensitive datasets are required to maintain a stringent version history, while others do not need such protection. Preserving extensive blob version and snapshot history for all datasets in their storage account is cost-prohibitive. They can now use metadata and tags with Azure Storage Actions to flexibly manage the appropriate retention and lifecycle of versions and snapshots for their datasets.
Cost optimization based on naming patterns and file types: Many Azure Storage customers also have requirements to manage tiering, expiry and retention of blobs based on path-prefix, naming conventions or file-type. These attributes can be combined with blob properties, such as size, creation time, last modified or last accessed times, access tier, version counts, and more to process the objects as desired.
One-off processing of blobs at scale: In addition to ongoing data management operations, Azure Storage Actions can also be used for one-off processing of billions of objects. For instance, you can define tasks to rehydrate a large dataset from the archive tier, reset tags on part of a dataset when an analytic pipeline needs to be restarted, initialize blob tags for a new or changed process, or clean-up redundant and outdated datasets.
Getting started with Azure Storage Actions
We invite you to preview Azure Storage Actions for data management of your object storage. You can try the feature for free during the preview, paying only for transactions invoked on your storage account. Pricing information for the feature will be published before general availability. For the list of supported regions, please see the feature support page. To get started, refer to the quickstart guide to compose and execute your first data management task in minutes. To learn more, please check out the documentation for details.
The post Introducing Azure Storage Actions: Serverless storage data management appeared first on Microsoft Azure Blog.