
DirectML now supports Copilot+ PCs, powered by Snapdragon® X Elite Compute Platform
We are thrilled to announce that DirectML now supports Copilot+ PCs, powered by Qualcomm® Hexagon NPU in the Snapdragon® X Elite Compute Platform. Copilot+ PCs bring exceptional performance and energy efficiency, enabling amazing AI experiences on Windows. With DirectML, the foundational component for the Windows Copilot Runtime, developers can now target these machines to scale AI across Windows.
Upendra Kulkarni, Vice President – Compute Software Product Management at Qualcomm, echoes Microsoft’s sentiment: “With Snapdragon X Elite, we introduced industry-leading NPU with 45 TOPS of AI performance at incredible power efficiency. DirectML is a developer friendly ML programming interface that uses familiar DirectX API structure. By supporting DirectML on our NPU, developers are now able to easily access its phenomenal capability easily and can port their models from GPU to NPU with minimal effort. We collaborated extensively with Microsoft to optimize DirectML for NPU to maximize hardware performance. We are excited to be co-announcing this developer preview program.”
Getting started with DirectML on Copilot+ PCs
System Requirements
Ensure you have the correct versions of DirectML, ONNX Runtime (ORT), Windows and the minimum versioned Qualcomm® Hexagon NPU driver.
- DirectML minimum version of 1.15.2 (ARM64)
- ONNX Runtime minimum version of 1.18 (ARM64)
- Windows 11, version 24H2 or newer
- Qualcomm® Hexagon NPU Driver minimum version 30.0.31.250 or newer (instruction below)
Developer-environment set-up on your Copilot+ PC
Let’s walk through how you can utilize DirectML and ONNX Runtime to leverage a set of models on the Copilot+ PC powered by Qualcomm® Hexagon NPU. First, you need to ensure you have the latest Qualcomm® Hexagon NPU driver package. Setting up a Qualcomm dev account is your very first step:
- Create an account at https://qpm.qualcomm.com/
Now, log in with your account credentials and click the following link: Qualcomm Package Manager 3 and download the latest driver available. Then, follow the steps below to download the Qualcomm® Hexagon NPU Driver Package for Windows:
- Change OS from “Windows” to “Windows (ARM64)”
- Click Download (latest driver version available)
- Extract QHND.Core.1.0.0.5.Windows-ARM64.zip
- Run PreAlpha_QCHexagon_NPU_Driver installer
- Verify that “Neural processors > Snapdragon® X Elite … NPU” has version 30.0.31.250 in device manager (see Release_Notes.pdf in the extracted ZIP file for details)
With the driver package installed and the minimum versions of DirectML, ORT and Windows enabled, try this ESRGAN super-resolution model sample to build a C++ application that runs on the new Copilot+ PCs!
Current capabilities and limitations
DirectML is rapidly expanding, and we are simplifying how developers can utilize the various local accelerators, hardware variations and frameworks across Windows. There are constraints with what is available today and they are highlighted below:
- C++ Developers need to depend on DirectML 1.15.2 as a redistributable package within their app (reference the sample above).
- NPU selection through the Python API for ONNX Runtime is not available currently but is coming soon!
- There are specific models that DirectML guarantees will work on Qualcomm® Hexagon NPU. Please leverage these exact ONNX versions during model sampling.
- Developers will experience error code DXGI_ERROR_UNSUPPORTED (0x887A0004) stating “The specified device interface or feature level is not supported on this system” when attempting to use models outside of supported models.
- For testing any models outside of our supported list, developers may enable windows developer mode (settings/systems/for developers). Models that are run in this mode may have undefined behavior.
We are excited for this initial release and the continued expansion of DirectML on Copilot+ PCs. Stay tuned for more capabilities and announcements as we continue our investment in this space.
DirectML unlocks NPUs for web-based machine learning with WebNN NPU Developer Preview
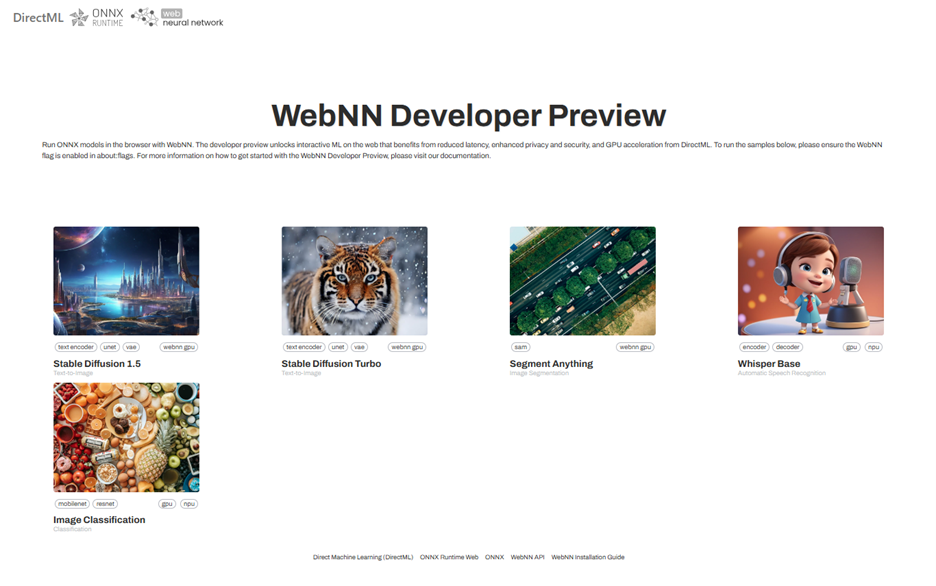
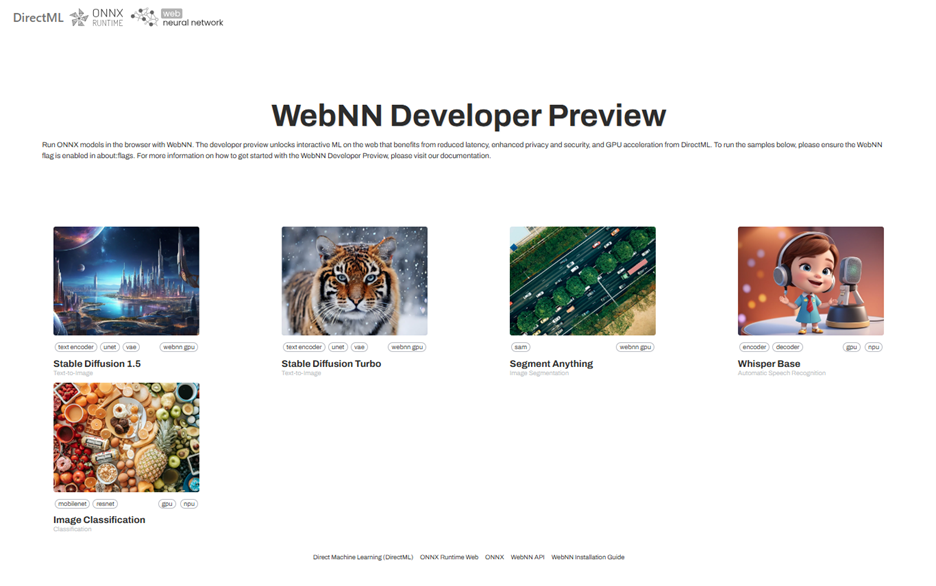
At Build, we launched the WebNN Developer Preview across Windows GPUs, and showcased initial support for NPUs, powered by DirectML. We are excited to announce that web developers can now leverage the power of NPUs on Windows devices with the latest release of DirectML and WebNN Developer Preview. This release enables support for an initial set of models on Intel® Core™ Ultra processors with Intel® AI Boost and the Copilot+ PC, powered by Qualcomm® Hexagon™ NPUs that you can try out today on the WebNN Developer Preview website.
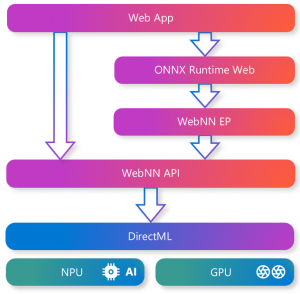
WebNN is an emerging web standard that defines how to run machine learning models in the browser and offers new possibilities for bringing AI innovations to the web. It defines how to interface with hardware acceleration APIs such as DirectML, enabling web sites to leverage the GPU or NPU on a user’s PC to run AI locally. DirectML, a key foundational component of the Windows Copilot Runtime, uniquely simplifies how developers can scale their AI innovations, through a single, cross-hardware DirectX API that provides a secure, consistent, performant experience across different hardware architectures. WebNN also supports integration with machine learning frameworks, like ONNX Runtime Web (ORT Web), which is part of the ONNX Runtime project. ORT Web is a JavaScript library that enables you to run ONNX models in the web browser and extends the Execution Provider (EP) framework to include WebNN as an EP.
Enabling DirectML across NPUs with WebNN is only possible with the support and close collaboration of hardware partners like Intel. Intel Fellow, Moh Haghighat, remarked: “Intel is excited that WebNN and DirectML can now provide countless web developers the ability to harness the power and efficiency of Intel’s NPU for creating and executing innovative machine learning features in web applications on AI PCs. We eagerly look forward to the new possibilities that WebNN and DirectML bring to web developers and the web users around the world who will benefit from faster, smarter, and more engaging web applications.”
This is just the beginning of our journey to enable AI on the web with WebNN and DirectML. Stay tuned for upcoming releases that will include more functionality and broader model coverage, including generative AI models.
Get started with the WebNN Developer Preview
With the WebNN Developer Preview, powered by DirectML and ORT Web, you can run ONNX models in the browser with hardware acceleration and minimal code changes.
To get started with WebNN on DirectML compatible devices you will need:
- Window 11, version 24H2 or newer
- Insider version of Edge (exact instructions provided below)
- The latest driver from our WebNN NPU Partners:
- Intel® Core™ Ultra NPU Driver for Windows
- Qualcomm® Hexagon NPU Driver Package for windows (see instruction set above)
Now that you have the latest NPU driver installed, here are the exact steps required to sample models with the WebNN framework.
Enabling Insider version of Edge for WebNN Dev Preview
- Microsoft Edge Canary or Dev Channel with WebNN flag enabled in about:flags
- Download from https://www.microsoft.com/en-us/edge/download/insider
- Run installer
- Navigate to about://flags
- Search for “Enables WebNN API” and change it to “Enabled”
- Exit browser
- Download DirectML redistributable:
- Download DirectML from https://www.nuget.org/packages/Microsoft.AI.DirectML/1.15.2
- Rename microsoft.ai.directml.1.15.2.nupkg to microsoft.ai.directml.1.15.2.nupkg.zip and extract it
- Copy microsoft.ai.directml.1.15.2.nupkg.zipbin-windirectml.dll to the appropriate directory (replace with x64 on Intel devices and arm64 on Qualcomm devices):<
- Edge Dev: “C:Program Files (x86)MicrosoftEdge DevApplication129.0.2779.0”
- When the dialog asks for Administrator permission, choose “Continue”
- Edge Canary: “%LOCALAPPDATA%MicrosoftEdge SxSApplication129.0.2779.0”
- Note the following on copying Directml.dll to Edge directory:
- The version-specific directory (129.0.2779.0) may differ on your machine
- New versions of Edge may require directml.dll to be recopied to the directory
- Edge Dev: “C:Program Files (x86)MicrosoftEdge DevApplication129.0.2779.0”
- Launch Edge insider:
- Open terminal and change your working directory to the Edge Insider build:
- If using Edge Dev: “C:Program Files (x86)MicrosoftEdge DevApplication”
- If using Edge Canary: “%LOCALAPPDATA%MicrosoftEdge SxSApplication”
- .msedge.exe –use-redist-dml –disable_webnn_for_npu=0 –disable-gpu-sandbox
- Open terminal and change your working directory to the Edge Insider build:
Now, you can run samples with the WebNN Framework by navigating to aka.ms/webnn and choosing either Image Classification or Whisper Base samples (and don’t forget to click the ‘npu’ button) or by directly linking here:
MobilNetV2 NPU Selected / ResNet50 NPU Selected / EfficientNetV4 NPU Selected / Whisper Base NPU Selected
Note, model start up times may be >1 minute; NPUs are in a rapid optimization stage so compile times will improve as we move WebNN to production trials. For more instructions and information about supported models and operators, please visit our documentation.
Additional links
To find out more information, we encourage you to visit these sites below:
- aka.ms/directml
- DirectML GitHub
- WebNN Developer Preview samples
- WebNN Developer Preview documentation
- WebNN API
- aka.ms/windowscopilotruntime
Looking ahead
DirectML is excited to continue to expand support across Copliot+ PCs and frameworks like WebNN and the ONNX Runtime. Stay tuned for more exciting updates as we continue to innovate and bring cutting-edge AI capabilities that allow you to scale your AI innovations across Windows.
As always, we appreciate your feedback and would like to learn from your experiences with NPU support in DirectML. To provide feedback and report issues, use the GitHub issues on the DirectML repository or provide general feedback at aka.ms/directml feedback hub. Make sure to include the details of your device, your Windows build, your DirectML application and your machine learning model when reporting an issue and/or feedback!